防火墙要开的话,一定要把内核参数优化,否则会随机丢包 /etc/sysctl.conf
net.netfilter.nf_conntrack_max = 9999999
net.netfilter.nf_conntrack_buckets = 1048576
还有帖子上提到的tcp丢包,高并发下centos以外的新系统默认锁4kqps上限,可以改成10w(centos默认为26w)
net.ipv4.tcp_max_orphans = 100000
防火墙要开的话,一定要把内核参数优化,否则会随机丢包 /etc/sysctl.conf
net.netfilter.nf_conntrack_max = 9999999
net.netfilter.nf_conntrack_buckets = 1048576
还有帖子上提到的tcp丢包,高并发下centos以外的新系统默认锁4kqps上限,可以改成10w(centos默认为26w)
net.ipv4.tcp_max_orphans = 100000
感觉和跟踪连接数没有太大的关系,后端是支持 HTTP/2 的,CloudFlare 的边缘服务器应该是会复用连接的
服务恢复了,我看一下数据面板
当前设置值
cat /proc/sys/net/netfilter/nf_conntrack_max
当前使用值
cat /proc/sys/net/netfilter/nf_conntrack_count
可以用命令看一下当前防火墙使用情况,就知道是不是防火墙丢包了
262144
18085
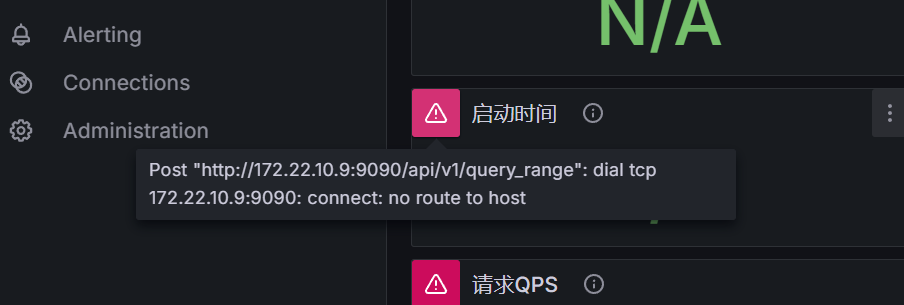
我这里 Grafana 的数据成直线了,数据不知道为什么停止了采集,我看看原因
现在连接数在 1.8k 的样子,服务正常,但是刚刚不知道为什么不正常,我试试重启一次 Sparkle 看看是不是刚刚启动的时候,有死连接之类的问题卡住
$ cat /proc/sys/net/netfilter/nf_conntrack_count
123596
我看到这个有点高
服务恢复后这个值在缓慢下降,现在我再重启一次,观察一下是不是会到 MAX,我怀疑刚刚半断网与此有关.
感觉并不是特别高,我看了一下整个启动过程,最多就一半,然后慢慢就下去了
我装个 node_explorer 看看 OS 情况
这些是系统内核的问题了,和代码无关了吧,就这三种原因
1.打开文件数受到1024限制,引起无法建立网络连接
2.防火墙丢包,不过看来并不是
3.tcp丢包,默认限制4k
以前踩过的坑了,,,帖子上特别有列举的内核优化
调了一下,再给个压力,然后我中间重启 Sparkle ,看看重启期间还会不会直接顶满
现在加到了 4194304,原来是 262144
我来了,你看看,现在是非高峰期,你可能要预留2到3倍这样,才能避免用满
爆了,临死之前监测到的 QPS 是 2.94k,然后监测就离线了
我看下堆栈转储
如果现在压力还在给,那我会说现在 web 控制台的流畅程度恢复了正常,感觉应该没有继续丢包。之前丢包的时候我连 arthas 都挂不上去。
我现在重启一次,看看会不会重启期间表满
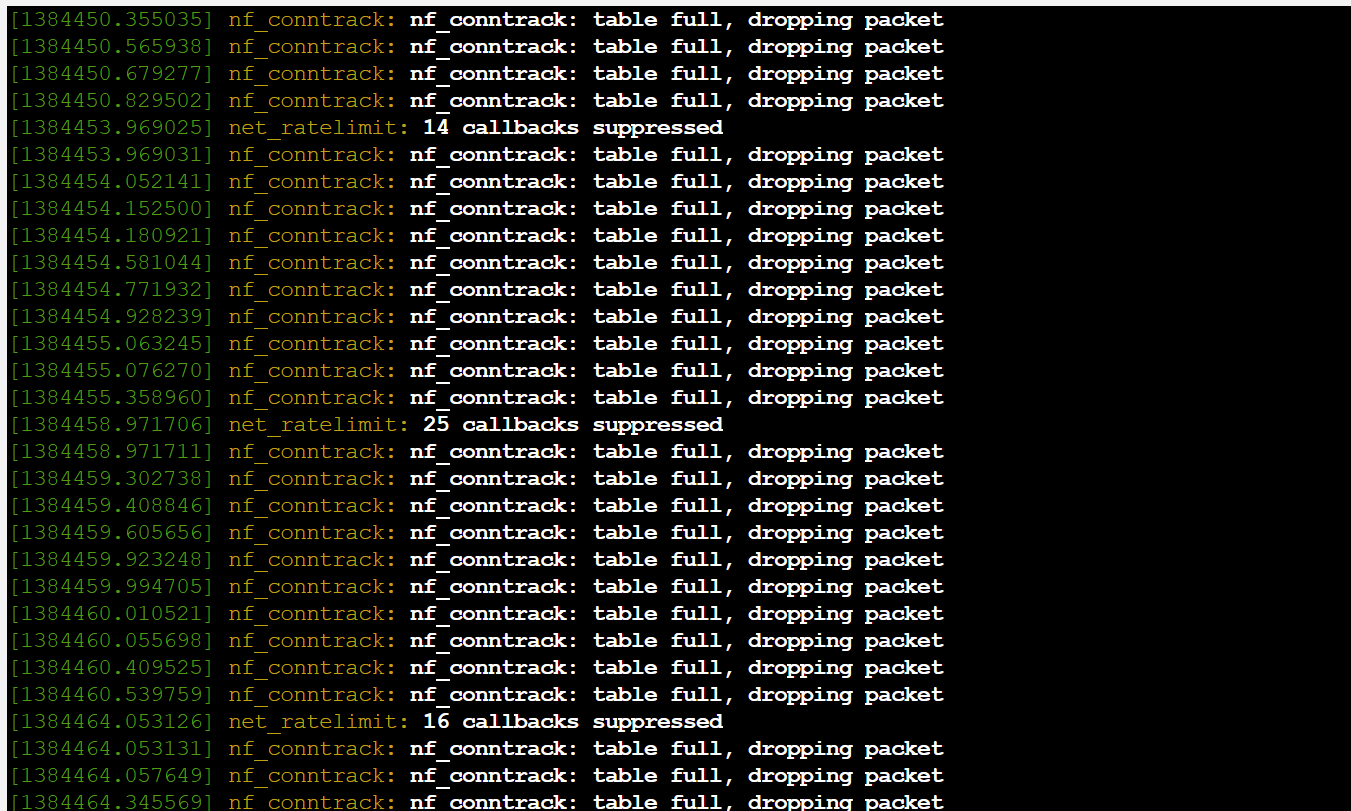
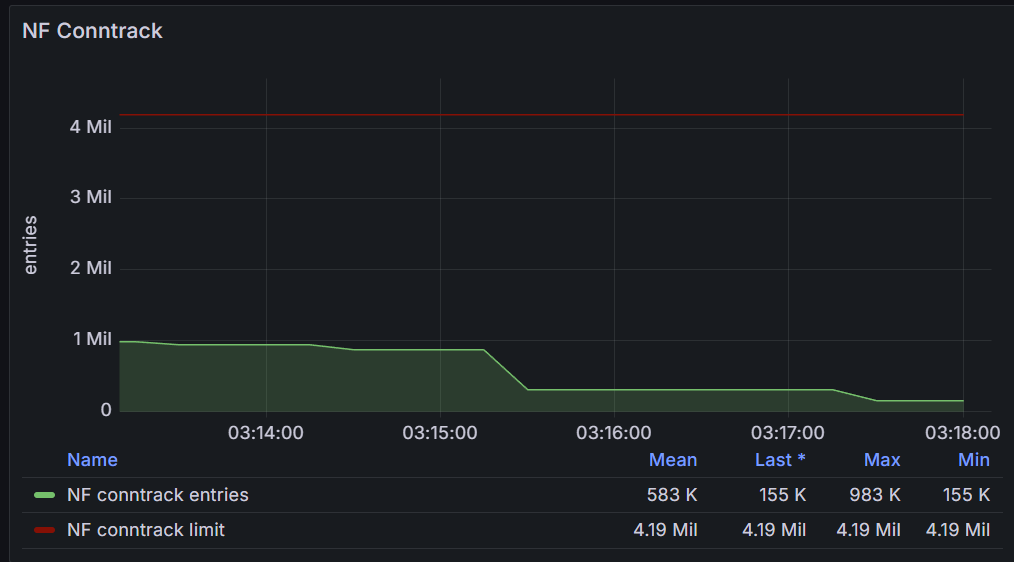
看起来现在 netfilter 表状态不错,峰值 qps 2.75k
ksoftirqd 爆了,让我检查一下,这防火墙指定是关不得的
中断积攒的太多了,SSH 现在出现明显延迟
新连接建立似乎有点问题了
nf_conntrack_count 现在是 900903
现在给我的感觉不像是应用有问题,而是系统或者网络层出问题了,因为我看 Java App 现在跑的挺好的,就是一直套接字关闭。
这个改了吗?这个没改的话,流量大也会tcp丢包
防火墙那个是整个系统丢包,,这个的话是仅针对tcp
再压 15 分钟就可以停了,我这里的 node_exporter 已经跑起来了开始采集数据了
连接数已经不是问题了,检查过连接数正常(1.4k 的连接数)。但是包数量级不对,现在在检查网络栈。
看看能不能降低一半的流量,现在流量太高,采集数据采集不了(数据采集也是通过本地网络传输)。
好了,调度流量比例减少一半
现在不是仅仅是网络在丢包,本地回环也在丢(( 软中断数量疑似太多了