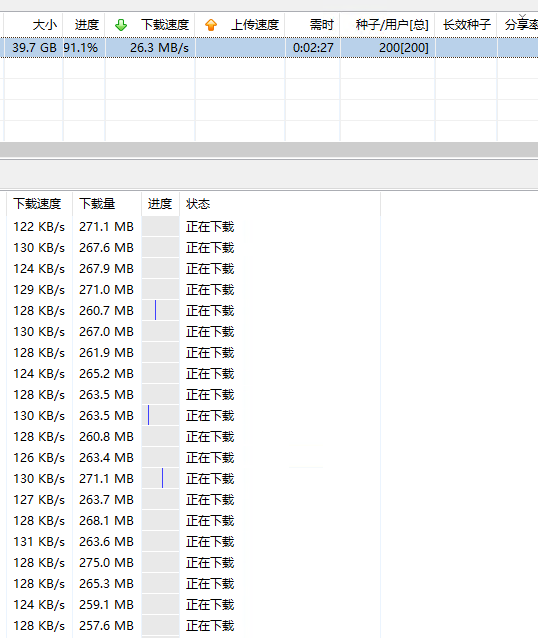
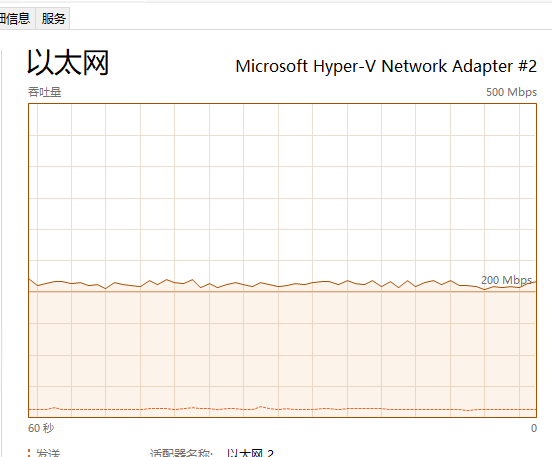
http还有办法增加线程吗?一些单线程限速128KB/s的下载,,,200线程最多跑26MB/s
文件蜈蚣这些其它下载器已经支持2000线程
什么时候把客户端字符串屏蔽做出来,每个peerid都不一样,最近好多种子都是Taipei-Torrent dev (n/a)



新的做种状态反吸血,我倒是没什么好的想法,基本上只能ip黑名单或者检测对方下载进度汇报
毕竟BT不像HTTP可以弹出js,验证码等来验证客户端是否合法
我唯一能想到的类似HTTP原理最好的办法就是,让对方客户端过一次人机验证,可以让比特彗星每一个做种任务可以申请一个临时的64KB内存,然后队列依次对每一个已连接peer询问要下载64KB数据写入临时申请的缓冲内存里,达到64KB或者20秒(一般建立连接后开始有速度需要10秒)内收到任何数据就立即断开,避免任务过多引起下载流量产生过大,只取64KB不需要对完整一个区块校验,如果对方回应则判断为绿色笑脸,如果对方未回应则保持黄脸,检测未通过则对其红脸加入拉黑,增加一个新选项卡状态显示,等待反吸血检测队列排队状态便于观察,如果没有任何peer则释放为这个任务申请的内存,避免运行上千任务时候引起不必要的内存泄漏
我想我这种反吸血方式比检测自身上传大小和对方进度是否发生变化更为精准
webgui里面没有peerid的信息显示
谷歌推出新的压缩引擎,什么时候支持下zstd
版本 123.0.2420.97 (正式版本) (64 位)
已经默认支持
Accept-Encoding:
gzip, deflate, br, zstd
压缩CPU效率是br的三倍
https://chromestatus.com/feature/6186023867908096
现有的tracker程序已经支持zstd,种子市场内可使用
http://49.12.76.8:2710/scrape
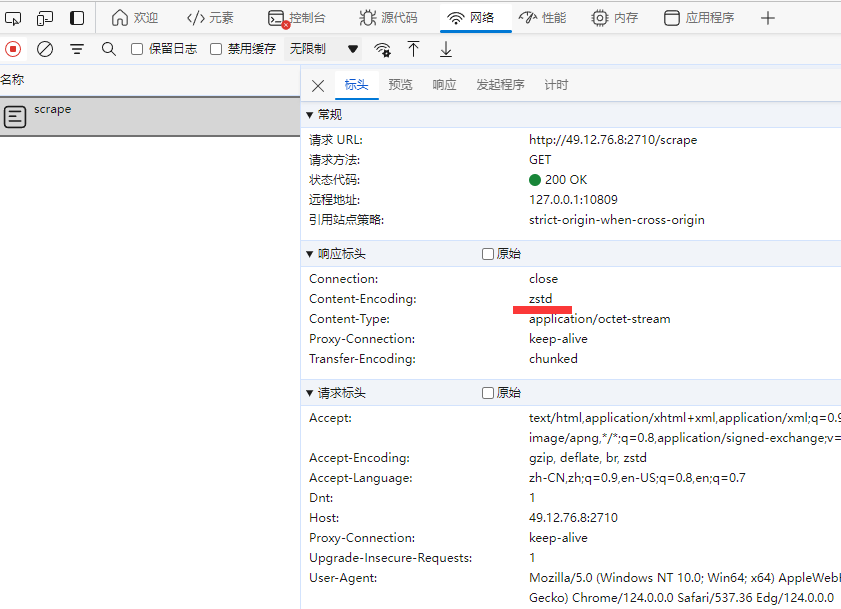
如果tracker强制使用zstd返回结果的时候,比特彗星客户端现在不支持zstd,会返回错误Unsupported tracker response format.

2.07版本请求一个udp tracker会发生2次重复包请求,会导致浪费一倍的流量

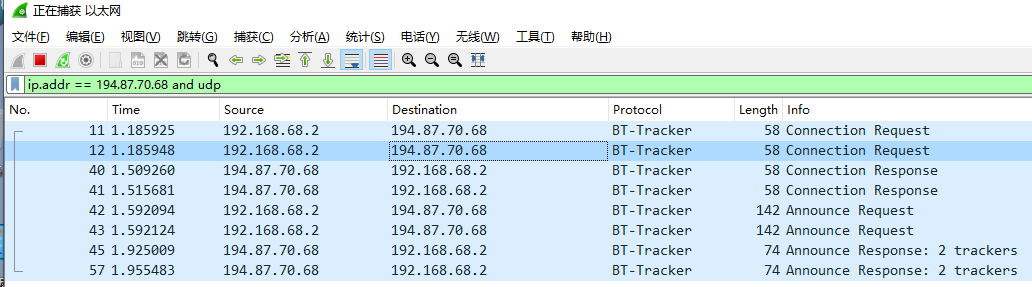

只有比特彗星会发生这种重复包情况,不知道哪个版本开始的,,,握手包和数据传送包都是重复2次请求